英伟达发布超长上下文推理芯片Rubin CPX 算力效率拉爆当前旗舰
财联社9月10日讯(编辑 史正丞)全球人工智能算力芯片龙头英伟达周二宣布,推出专为长上下文工作负载设计的专用GPU Rubin CPX,用于翻倍提升当前AI推理运算的工作效率,特别是编程、视频生成等需要超长上下文窗口的应用。
英伟达CEO黄仁勋表示,CPX是首款专为需要一次性处理大量知识(数百万级别tokens),并进行人工智能推理的模型而构建的芯片。
需要说明的是,Rubin就是英伟达将在明年发售的下一代顶级算力芯片,所以基于Rubin的CPX预计也要到2026年底出货。下一代英伟达旗舰AI服务器的全称叫做NVIDIA Vera Rubin NVL144 CPX——集成36个Vera CPU、144块Rubin GPU和144块Rubin CPX GPU。

(NVIDIA Vera Rubin NVL144 CPX机架与托盘,来源:公司博客)
英伟达透露,搭载Rubin CPX的Rubin机架在处理大上下文窗口时的性能,能比当前旗舰机架GB300 NVL72高出最多6.5倍。
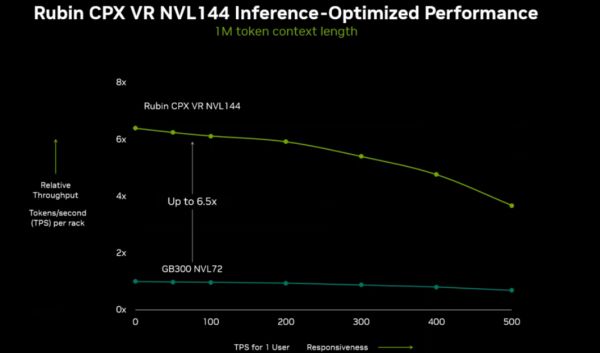
据悉,下一代旗舰机架将提供8 exaFLOPs的NVFP4算力,比GB300 NVL72高出7.5倍。同时单个机架就能提供100TB的高速内存和1.7PB/s的内存带宽。
言归正传,英伟达之所以要在Rubin GPU边上再配一块Rubin CPX GPU,自然是为了显著提升数据中心的算力效率——用户购买英伟达的芯片将能赚到更多的钱。英伟达表示,部署价值1亿美元的新芯片,将能为客户带来50亿美元的收入。
为何需要两个GPU?
作为行业首创之举,英伟达的新品在硬件层面上分拆了人工智能推理的计算负载。
英伟达介绍称,推理过程包括两个截然不同的阶段:上下文阶段与生成阶段,两者对基础设施的要求本质上完全不同。

上下文阶段属于计算受限(compute-bound),需要高吞吐量的处理能力来摄取并分析大量输入数据,从而生成首个输出token。相反,生成阶段则属于内存带宽受限(memory bandwidth-bound),依赖高速的内存传输和高带宽互联(如 NVLink),以维持逐个token的输出性能。
当前顶级的GPU都是为了内存和网络限制的生成阶段设计,配备昂贵的HBM内存,然而在解码阶段并不需要这些内存。因此,通过分离式处理这两个阶段,并针对性地优化计算与内存资源,将显著提升算力的利用率。
据悉,Rubin CPX专门针对“数百万tokens”级别的长上下文性能进行优化,具备30petaFLOPs的NVFP4算力、128GB GDDR7内存。
英伟达估计,大约有20%的AI应用会“坐等”首个token出现。例如解码10万行代码可能需要5-10分钟。而多帧、多秒的视频,预处理和逐帧嵌入会迅速增加延迟,这也是为什么当前的视频大模型通常仅用于制作短片。
英伟达计划以两种形式提供Rubin CPX,一种是与Vera Rubin装在同一个托盘上。对于已经下单NVL144的用户,英伟达也会单独出售一整个机架的CPX芯片,数量正好匹配Rubin机架。


海量资讯、精准解读,尽在新浪财经APP
相关知识
英伟达发布超长上下文推理芯片Rubin CPX 算力效率拉爆当前旗舰
死磕中国市场?英伟达被曝将出“中国特供版”AI芯片
Meta推出新版自研AI芯片:性能较上代提高三倍,降低对英伟达依赖
芯片突传大消息!美国商务部部长改口
美媒曝拜登政府考虑对华实施新的芯片制裁,英伟达股价闻声下跌
英伟达:长期对华实施芯片出口管制会致美国产业失去竞争机会
为维持对华出口,美国这家半导体公司考虑“学”英伟达
24年前的思科?英伟达市值登顶全球第一后“泡沫论”再起,但黄仁勋已将目标瞄准各国政府
南昌38岁芯片天才,半年收获176亿财富
全球首家!法国监管机构起诉英伟达
推荐资讯




- 1李沁肖战已同居领证? 李沁肖 49374
- 2闫妮老公邹伟平简历 闫妮前 45126
- 3王凯蒋欣承认已有一子? 结 41028
- 4王灿前夫 王灿的第一任老公 36795
- 5汪希玥回北京过年,怎料见到汪 32880
- 6霍启山与霍启仁对嫂子郭晶晶的 29891
- 7张佳宁和宋轶长得像 同属甜美 25986
- 8央视主持孙小梅丈夫曝光,是大 21391
- 960年代,洪秀柱(右后)与父 20341
- 10佟丽娅事件是什么 佟丽娅回应 19647



